
Bryophytes
Non-vascular land plants - liverworts, mosses, and hornworts.



Máme-li více výběrů než dva, nemůžeme řetězit dvouvýběrové t-testy ani jejich neparametrické varianty, ale musíme použít speciální metody výpočtu označované obecně jako ANOVA a její neparametrické obdoby. Dostáváme se na půdu lineárních modelů a jejich neparametrických rozšíření a tedy půdu již poměrně komplikovanou 🙂
Všechny na tomto postu uvedené testy naleznete v 9. Lekci R.
Mám data z více výběrů, které jsou nezávislé, ale mohou být závislé.
1a Data jsou poměrová a splňují podmínku homogenity variancí a pocházejí ze souborů s normálním rozdělením . . . 2 ANOVA
1b Data výše uvedenou podmínku nesplňují nebo nejsou poměrová . . . 3 neparametrické testy
2a Všechny výběry nezávislé . . . klasická ANOVA
| ANOVA | vyvážený design | nevyvážený design |
| jednofaktorová | Typ I | Typ III |
| hlavní efekt | Typ I | Typ II |
| vícefaktorová | Typ I | Typ III |
| nested | Typ I | Typ III |
2b Alespoň jeden výběr závislý . . . RMANOVA
Klasická ANOVA i RMANOVA mohou pracovat s faktory s pevnými efekty i náhodnými efekty.
3a Všechny výběry nezávislé . . . Kruskal-Wallis test
3b Alespoň jeden výběr závislý . . . Friedmanův test
Tento test je základní a používáme ho, chceme-li posoudit hypotézu o rovnosti průměrných hodnot více než dvou výběrů. Předpoklady použití ANOVA jednoduchého třídění jsou:
Užití si můžeme demonstrovat na následujících příkladech:
1. Nejprve testuji poměr variance uvnitř definovaných skupin (typ vegetace nebo typ návštěvníka hradu podle vztahu k historii) a rozptylu celkového souboru získaných dat. Jde tedy v podstatě o F-test. Rozptyly zde jsou označovány jako MS (F= MS(celek)/suma MS(ve skupinách)). Rozptyly jsou určeny jako podíly součtu čtverců odchylek od průměrů a počtu stupňů volnosti. Přehled informací k prvnímu kroku je na tabuli.

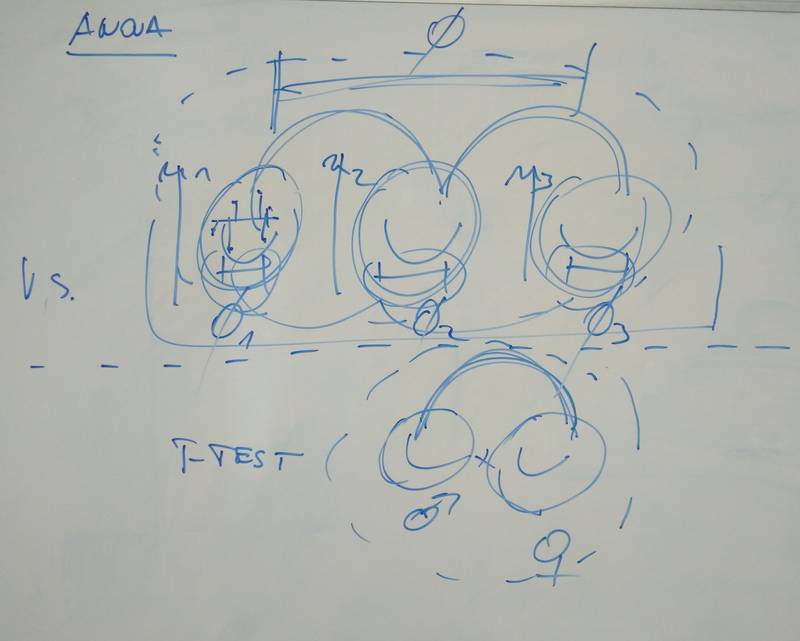
2. Pokud zjistím, že hodnota F je vyšší než kritická hodnota pro daný počet stupňů volnosti (= p je menší než stanovená hladina významnosti), pak vím, že v mém souboru dat existují rozdíly mezi skupinami, musím se proto dále ptát: “Jaké skupiny vegetace nebo jaké skupiny návštěvníků hradu se od sebe liší?” Následuje tedy fáze mnohonásobného porovnávání, kdy se testuje rozdílnost skupin pomocí tzv. post-hoc testů. K nim je obvykle nutné znát dosažené hodnoty rozptylů, stupně volnosti a počet měření pro jednotlivé testované skupiny. Těchto testů je mnoho, obecně se používá Tukeyho post-hoc test, jehož výpočet je odvozen od t-testu a má variantu pro vyvážený i nevyvážený design. Kritické hodnoty pro jeho q statistiku lze nalézt na externím odkazu (R počítá přímo i hodnotu p). Přehled informací ke druhému kroku je na tabuli.

Analogií Tukeyho post-hoc testu je Dunnettův post-hoc test, kterým porovnáváme nikoliv všechny skupiny mezi sebou, ale všechny skupiny s kontrolní skupinou. Použije jej tedy, pokud provádíme experiment, kde máme jednu bezzásahovou skupinu (= kontrolu).
Další testům “klasické” ANOVA se budeme věnovat podrobněji v navazujícím kurzu.
Postup řešení výpočtu jednofaktorové ANOVA v MS Excel je na videu.Postup výpočtu Tukeyho post-hoc testu v MS Excel je na videu.Dunnettův post-hoc test se dá vypočítat i v MS Excel, jako je na externím videu. Ve STATISTICA jej najdete v dialogovém okně ANOVA Results na kartě post-hoc úplně dole (pokud znáte směr, tak můžete použít jednostranného testu; nezapomeňte nastavit, která úroveň je kontrola).
Postup řešení výpočtu jednofaktorové ANOVA v MS Excel je na videu. Postup výpočtu Tukeyho post-hoc testu v MS Excel je na videu. Dunnettův post-hoc test se dá vypočítat i v MS Excel, jako je na externím videu. Ve STATISTICA jej najdete v dialogovém okně ANOVA Results na kartě post-hoc úplně dole (pokud znáte směr, tak můžete použít jednostranného testu; nezapomeňte nastavit, která úroveň je kontrola).
Je-li One-way ANOVA analogií dvouvýběrového t-testu pro více výběrů, pak RMANOVA je obdobou pro párový t-test, kde máme více opakování než jedno. Tento test použijete v případech, když výběry nejsou vzájemně nezávislé – typicky, když měříte jeden objekt více než dvakrát. Výpočet v R se odvíjí od výpočtu vícefaktoriální ANOVA (viz navazující kurz).
Použití MS Excel pro tento výpočet máte na externím zdroji.
Pokud jsou předpoklady pro použití ANOVA výrazně porušeny, používáme Kruskal-Wallis test. Ten je neparametrickou obdobou testu (jedno)faktorové ANOVA. Podobně jako Mann-Whitney test, je i výpočet Kruskal-Wallis testu založen na pořadí. Používáme ho v případě, kdy je zjevně porušena normalita v rozložení měřených dat – což se v terénu obvykle stává často – nebo máme ordinální data. Kruskal-Wallis test se běžně používá a v mnoha případech je jeho použití správnější než ANOVA jednoduchého třídění. Vše podstatné je na tabuli.

Tabulka kritických hodnot je na např. na externím odkazu 1 nebo externím odkazu 2. Také u Kruskal-Wallis testu je v případě prokázání rozdílů mezi skupinami nutné provést test shody dvojic měřených úrovní. Existuje mnoho takových testů, ale nejčastěji se provádí Mann-Whitney testem pro jednotlivé páry s upraveným p podle Bonferoniho korekce – blíže na externím odkazu.
STATISTICA má tento test schován v nabídce karty “Nonparametrics” pod označením “Comparing multiple indep. samples (groups)”.
Je-li Kruskal-Wallis test analogií Mann-Whitney testu pro více výběrů, pak Friedmanův test je obdobou pro Wilcoxonův test, kde máme více opakování než jedno. Tento test použijete v případech, když výběry nejsou vzájemně nezávislé – typicky, když měříte jeden objekt více než dvakrát a zároveň máte porušeny pravidla pro použití RMANOVA (především často nemáte “normální” data).
Příklady jsou stejné jako v případě RMANOVA, jen data nesplňují podmínky použití RMANOVA.
Použití MS Excel pro tento výpočet máte na externím zdroji.
Neparametrické metody jsou určeny primárně pro testování statistických hypotéz týkajících se nominálních a ordinálních dat – jsou na nich definovány. V případě dat nominálních vyhodnocujeme četnosti – jen ty mají kvantitativní charakter, jinak vlastní nominální data mají informaci kvalitativní (pohlaví, barva, typ čehokoliv). Testování hypotéz u ordinálních dat se děje na základě pořadí zjištěných hodnot – v testech se nepracuje se přímo s měřenými hodnotami, ale s jejich pořadími.
Využít tyto metody lze i pro data vyšší úrovně. V případě, že tato data nesplňují některou z podmínek testů určených pro tyto data, a my je musíme testovat, pak nemáme na výběr, a použijeme neparametrických metod. Nicméně, pokud je to možné, měli bychom na poměrová data použít metod parametrických.
První skupinou metod jsou metody definované na nominálních datech a určeny tak jsou především pro testování hypotéz spojených s četnostmi výskytu.
Hodnoty důležité pro výpočet chí-kvadrát testu jsou obvykle zjistitelné z kontingenční tabulky našich dat. Vzorce pro výpočet jsou uvedeny u jednotlivých typech testů.
MS Excel je schopen jej vypočítat pomocí funkce CHITEST (nové verze používají funkci CHISQ.TEST), jen si budete muset sami napsat nebo vypočítat očekávané hodnoty (navíc MS Excel vrací jen hodnotu p a nikoliv chí-kvadrátu a d.f., přestože návod tvrdí opak).
Nejčastěji používáme chí-kvadrát test ve dvou typech případů:
Základní informační shrnutí je na tabuli.

Základní informační shrnutí je na tabuli.

V tomto případě použití nám “chybí” očekávané hodnoty – ty se pro každou buňku matice 1. proměnná versus 2. proměnná určí jako podíl součinu součtu četností daného řádku a součtu četností daného sloupce a celkového počtu pozorování (= vzorec je zeleně na předchozím obrázku).
V případě software STATISTICA je není nutné počítat, program to udělá sám – video.
Při výpočtech pamatujte na omezení chí-kvadrát testu, že žádná očekávaná četnost nesmí být nulová (nulou dělit nelze) a neměla by být menší než 1, což se běžně stává při měřených četnostech 0, a maximálně 20 % všech četností může být menších než 5 (žádná hodnota pod 5 u 2×2 tabulek). Pokud je menších četností více, je nutno použít Yatesovu korekci (červeně na předcházejícím obrázku), kterou se doporučuje provádět jen v 2 x 2 tabulkách.
K tomu, abyste mohli vypočítat chí-kvadrát s Yatesovou korekcí v MS Excel, budete muset znát funkci MS Excel ABS, která vrací absolutní hodnotu čísla nebo čísla vyjádřeného výrazem.
Velkým problémem chí-kvadrát testu je to, že hodnota p je pouze odhadem, neboť rozdělení náhodného výběru nominálních dat je jen aproximací chí-kvadrát rozdělení. Tato aproximace je nespolehlivá u malých počtů měření a především v 2×2 kontingenčních tabulkách. Mám-li 2×2 kontingenční tabulku o malých četnostech, včetně nuly, pak se jako nejvhodnější varianta doporučuje použít Fisherův exaktní test. Testuje se nulová hypotéza, že rozdělení objektů podle dvou kritérií je odlišné od hypergeometrického rozdělení. Počítá se pouze hodnota p, kterou se testuje odlišnost sloupců od řádků. Vzorec pro výpočet je:
p = ((a+b)! (c+d)! (a+c)! (b+d)!)/(a! b! c! d! n!)
kde p je hladina významnosti, a, b, c, d jsou hodnoty v kontingenční tabulce v uspořádání SZ, SV, JZ, JV a n = a+b+c+d. Obrovskou výhodou je možnost použití tohoto testu, i když se některá z hodnot a,b,c,d rovná nule, neboť 0!=1.
V MS Excel je k výpočtu znát další funkci – FAKTORIÁL.
RealStatistics podporuje Fisherovy exaktní testy v kontingenčních tabulkách 2×2 až 5×2 a 3×3.
Jde o alternativu chí-kvadrát testu. Testují se v něm rozdíly mezi výběry (dvouvýběrový) nebo výběrem a teoretickým rozdělením (jednovýběrový test dobré shody) v relativních kumulativních četnostech (absolutní hodnota rozdílu). Největší rozdíl je pak testovacím kritériem, které je posuzováno oproti tabelované kritické hodnotě pro odpovídající hladinu významnosti a počet stupňů volnosti (d.f. = počet měření (n)).
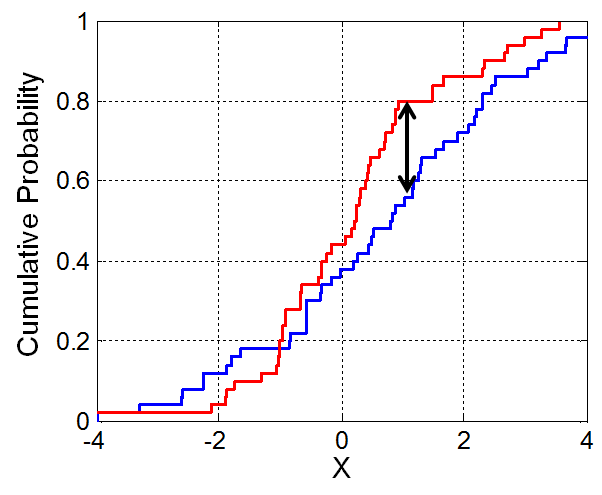
Jednovýběrový Kolmogorov-Smirnov test se nejčastěji používá k testování shody rozložení dat s teoretickým rozdělením, nejčastěji normálním.
Výpočet K-S testu v MS Excel je na videu.
Výhodou Kolmogorov-Smirnov testu je jeho neomezení počtem četností výskytu v očekávaných hodnotách méně než 5, a tak ho lze využít jako alternativu, kde není možno použít chí-kvadrát test, nicméně stále platí, že v žádné skupině nesmí být 0.
Pokud z nějakého důvodu potřebujete testovat poměry a nikoliv četnosti, tak nemůžete použít chí-kvadrát test (který asi jako první nabízí), protože velikost souboru ovlivňuje kritickou hodnotu chí-kvadrát testu a je tedy rozdíl jestli jste v pokusu měli 10, 25 100, nebo 2500 objektů a převodem na procentický poměr byste všechny výše uvedené četnosti převedli na 100.
V případech nutnosti testování poměrů se požívá z-test, který není předmětem naší výuky a návod na jeho výpočet najdete v učebnici R jako kapitolu Advanced R3.
Četnosti jsme se naučili vizualizovat pomocí histogramu, kromě něj můžeme použít klasické koláčové grafy a nejvhodnější je vizualizace pomocí mozaikových grafů (mosaicplots). Návod pro R včetně videa najdete v sedmé lekci R.
Další zde uvedené testy jsou určeny pro ordinální data a založeny jsou na porovnávání pořadí.
MS Excel je schopen přiřadit pořadí hodnotám funkcí, která se jmenuje rank. Zde nezapomínejte používat opravný faktor, jehož hodnotu musíte přičíst k hodnotě získané funkcí rank – je to nutné, pač ve Vašich datech může být jedna hodnota vícekrát a funkce rank jim všem přiřadí nejmenší hodnotu pořadí, což je pro tyto metody špatně – tam musíte mít v těchto případech průměrnou hodnotu pořadí těchto čísel.
Testujeme shodu rozdělení jedné měřené proměnné u dvou provedených výběrů. Jde o základní test sloužící k porovnání dvou výběrů (= jde o ordinální obdobu dvouvýběrového t-testu). Test vychází z pořadí a počtu měření. Základní informační shrnutí je na tabuli.

POZOR!!!
Vzhledem k tomu, že U je definována jako jakákoliv hodnota, která má být malá, když platí H1, tak jsou statisticky významné hodnoty testovacího kritéria nižší než daná kritická hodnota.
Lze brát nižší hodnotu U nebo (jak je uvedeno v učebnici) vyšší hodnotu U – pro oba postupy se tabulky liší.
Pro jednostranný test záleží na tom, jestli řadíte hodnoty od nejvyšší k nejmenší, nebo je řadíme od nejmenší k největší.
Srovnat lze i větší počet nezávislých výběrů, test se jmenuje Kruskal-Wallisův test (viz zde dole).
Používá se pro testování párových dat – jedna měřená proměnná u jednoho výběru, kde je každý objekt (jedinec, …) měřen dvakrát. Test je založen na pořadí rozdílů jednotlivých měření (= jde o ordinální obdobu párového t-testu). Základní informační shrnutí je na tabuli.

Srovnat lze i větší počet závislých výběrů, test se jmenuje Friedmanova ANOVA – k ní se však dostaneme až v navazujícím kurzu, jinak je tady dole.
Na tomto místě se podíváme na základní parametrické metody pro jeden a dva výběry – těmi jsou t-test a F-test. Definovány jsou, jak bylo zmíněno dříve, na poměrových datech a předpokladem jejich použití je normalita dat. Testovanými parametry jsou průměr (t-test) s využitím střední chyby průměru a rozptyl (F-test). Výpočty všech těchto parametrů jsme řešili dříve.
V praktické statistice se normální rozdělení nahrazuje t-rozdělením, které je mu velmi podobné. Jeho charakteristiky umožňují testovat hypotézy, které jsou vázány na průměr. Ty nás zajímají nejčastěji, a proto patří metody testování založené na tomto rozdělení k nejvýznamnějším základním testovacím metodám pro dva výběrové soubory. Nicméně v podstatě můžeme rozlišit tři typy možností nulových hypotéz, které obvykle testujeme různými t-testy.
V praktické statistice se normální rozdělení nahrazuje t-rozdělením, které je mu velmi podobné. Jeho charakteristiky umožňují testovat hypotézy, které jsou vázány na průměr. Ty nás zajímají nejčastěji, a proto patří metody testování založené na tomto rozdělení k nejvýznamnějším základním testovacím metodám pro dva výběrové soubory. Nicméně v podstatě můžeme rozlišit tři typy možností nulových hypotéz, které obvykle testujeme různými t-testy.
Průměr proměnné z dat získaných našim měřením se testuje oproti průměru teoretickému (= očekávanému průměru či známému průměru základního souboru), jímž může být např. hodnota uváděná v literatuře. Tohoto testu používáme např. při srovnávání výsledků našeho výzkumu s výzkumem předchozím.
Podstatou testu je podíl dvou hodnot – v čitateli je rozdíl průměru našich hodnot a teoretického průměru (který jsem našel např. v literatuře – třeba v Květeně ČR), ve jmenovateli je střední chyba průměru vypočítaná z našich dat. Výpočet průměru a jeho střední chyby jsme si ukázali v sekci charakteristiky dat. Všechny výpočty jsou uvedeny na tabuli a vlastní postup uvažování jsme si představili, když jsme si představovali princip testování hypotéz.
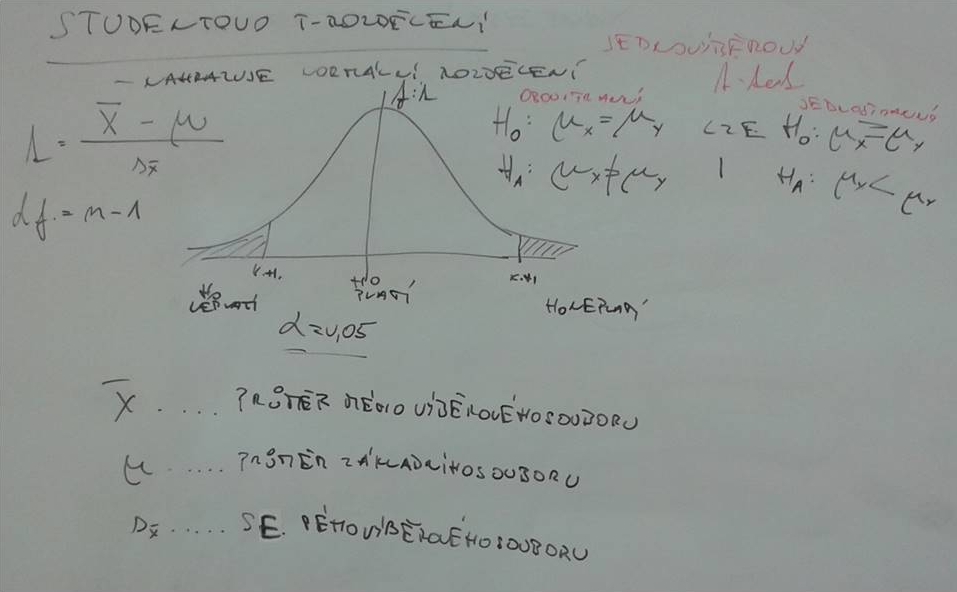
Jednovýběrový t-test.
Výpočet jednovýběrového t-testu v R naleznete v šesté lekci R.
Platí, že máme už dvě měření (na rozdíl od předchozí statistiky), ale obě měření nejsou vzájemně nezávislá – obvykle jde o dvoje měření na jednom objektu – je samozřejmé, že jde o měření jedné náhodné veličiny. Používá se např. při testování změny měřeného jevu na jedinci. Do testu ale v tomto případě nevstupují obě měření jako dva výběry, ale od jednoho měření (obvykle druhého) odečtu hodnotu druhého měření (obvykle se jedná o hodnoty z prvního měření). Pokud nedošlo ke změně mezi měřeními, pak by se tento rozdíl měl rovnat nule. Testuje se, jestli tomu tak opravdu je, tedy testuje se rozdíl měření (hodnoty rozdílu obou měření) oproti očekávanému průměru, jímž je v tomto případě 0 (tedy mí = 0). Vše podstatné je na tabuli.

Podstata párového t-testu.
Výpočet pérového t-testu v R naleznete v šesté lekci R.
Výpočet párového t-testu v MS Excel pomocí analytických nástrojů.
Prozatím jen na okraj zmiňme, že v praxi takové výzkumy zas až tak jednoduché nejsou, protože nevíme, co vše může být příčinnou změny – pokus je třeba vždy plánovat a obvykle je třeba mít nějakou kontrolní skupinu, kde nedošlo k žádnému zásahu. Navíc, pokud testuji rozdíly mezi dvěma skupinami, tak bychom měli nejprve vypočítat rozdíly v každé skupině a teprve tyto dva rozdíly testovat dvouvýběrovým t-testem, nebo vybrat jinou sofistikovanější metodu z těch, které budeme řešit v navazujícím studiu např. zde nebo v některých případech i zde.
Měřím jednu proměnnou ve dvou výběrech a testuji, jestli se neliší průměry těchto dvou výběrů. Oba výběry jsou na rozdíl od předchozího testu nezávislé. Kromě normality je dalším požadavkem, aby oba výběry měly stejnou varianci. Vzorec pro výpočet testu je odvozen od vzorce pro výpočet jednovýběrového t-testu. V čitateli je v tomto případě ale rozdíl průměrů obou výběrových souborů, ve jmenovateli je pak střední chyba průměru rozdílu obou průměrů. Výpočet této střední chyby je komplikovaný a vychází z podílů odhadované společné variance obou výběrů. Počet stupňů volnosti se pak rovná součtu počtu měření v obou výběrech sníženém o 2. Vše podstatné je shrnuto na tabuli.

Dvouvýběrový t-test.
Pokud je soubor měření dostatečně velký, tak není porušení pravidla stejné variance nijak zásadní. Pokud je soubor malý a variance diametrálně odlišná, pak se počítá “přibližné t” s přibližným počtem stupňů volnosti. Oba výpočty umí přes Analýzu dat MS Excel vypočítat. My však pro výpočet dvouvýběrového t-testu použijeme R v šesté lekci R.
Výpočet dvouvýběrového t-testu v MS Excel.
F-test je dvouvýběrovým testem, kterým se testuje shoda rozptylů těchto dvou výběrů. Používá se ve stejných případech, jako dvouvýběrový t-test. Rozdíl je v tom, že u t-testu se ptám po případné existenci rozdílu v průměru, ale u F-testu se ptám po případné existenci rozdílu ve variabilitě dvou výběrů.
Základní informace k testu jsou shrnuty na tabuli – jen doplňme, že v čitateli je obvykle hodnota rozptylu, která je větší – výsledkem je tak hodnota větší než 1. Existují ale i tabulky, které počítají s vyšší hodnotou ve jmenovateli – pak ale nulovou hypotézu zamítáme, když je hodnota testovacího kritéria menší než hodnota kritická. MS Excel je schopen spočítat obě varianty zadání vstupních dat (vstupní data vypadají stejně jako vstupní data pro párový t-test).
Výpočet F-testu v R naleznete v šesté lekci R.

F-test a jeho srovnání s t-testem.
Vlastní F-test obvykle používáme méně často než t-test (průměry nás zajímají obvykle častěji než variance), přesto v ekologii má variabilita stejně velký význam jako vlastní střední hodnota proměnné.
Nicméně význam F-testu je na úrovni našeho základního studia extrémní, pač F-test je podstatou porovnávání více než dvou výběrů v testu se jménem ANOVA (analýza rozptylu) – zde nahoře – a při testování lineárních regresních modelů.
POZOR!!!!! – mám-li více výběrů než dva (např. nemám samce a samice, ale mám čedič, vápenec a žulu), nemohu řetězit dvouvýběrové t-testy ani F-testy, ale musím použít metodu ANOVA. K tomu se ale ve výuce dostaneme až po přehledu neparametrických metod.
Všechny proměnné, které měříme, jsou náhodnými veličinami, . . . co to znamená?
Veličinu chápeme jako vyjádření výsledku měření výskytu nějaké charakteristiky (označované jako znak) nějakého jevu vázaného na objekt mého výzkumu. Problémem je, že všechna měření všech znaků charakteristických pro všechny jevy jsou vždy ovlivněny spoustou faktorů, které měřit nejsem schopen, ani při největší snaze. Tyto faktory mají za následek, že veličina pak ze své podstaty nemůže být nikdy změřena absolutně správně. Za různých konstelací neměřitelných a nesledovatelných podmínek pak může mé měření dopadnout různě. To je důvod, proč se měřené veličiny označují jako veličiny náhodné.
Z výše uvedeného plyne, že to, co konkrétně změřím, je pouze konkrétní realizace (daná v podstatě náhodou) této náhodně měřené veličiny z nekonečně velkého potenciálně možného počtu veličin. My jsme si toho vědomi a tak víme, že to, co jsme aktuálně změřili, je pouhou jednou variantou z obvykle nekonečného množství teoreticky změřitelných hodnot – měření mohu opakovat tolikrát, kolik my zbývá sil, a pokaždé změřím něco (trošku) jiného. Předpokládám ale, že různé konkrétní hodnoty mohu změřit s různou pravděpodobností. Jinak řečeno, určité hodnoty mohou být naměřeny častěji než hodnoty jiné.
Každá náhodná veličina tak má své rozdělení pravděpodobností měření konkrétních hodnot. Každá konkrétní hodnota je tak charakteristická pravděpodobností, že bude její hodnota změřena. Tuto skutečnost je pak teoreticky možné vyjádřit funkcí hustoty pravděpodobnosti, jež se často vyjadřuje grafem, který, vulgárně řečeno, vypadá jako funkční spojité vyjádření histogramu – na ose x jsou jednotlivé konkrétní hodnoty náhodné veličiny a na ose y je pak míra pravděpodobnosti výskytu takového hodnoty (vyjádřená v hodnotě funkce hustoty pravděpodobnosti). Plocha pod touto křivkou se pak rovná 100% pravděpodobnosti změření všech hodnot proměnné.
Dalším typem vyjádření pravděpodobnosti výskytu hodnoty náhodné veličiny je distribuční funkce pro libovolnou měřenou hodnotu, která udává pravděpodobnost, že reálně měřená hodnota bude menší než hodnota libovolně stanovená. Hustota pravděpodobnosti je derivací distribuční funkce.
Pokud nepředpokládáme existenci světa o sobě (jak jsou něm přesvědčeni např. Platón a Kant), pak průměr základního souboru není náhodnou veličinou – je konečný a Božsky správný. Nicméně stále platí, že průměr z náhodného výběrového souboru náhodnou veličinou je – teoreticky lze ze základního souboru udělat nekonečně mnoho náhodných výběrů a průměry těchto jednotlivých náhodných výběrů se budou lišit – tabule. V logice tohoto uvažování mohu kromě variability průměru jednoho náhodného výběru (dané směrodatnou odchylkou tohoto průměru) identifikovat také variabilitu průměru z průměrů. Tuto variabilitu nemusím ale počítat z nekonečného množství náhodných výběrů z daného základního souboru, ale mohu ji odhadnout na základě rozptylu a počtu měření, ze kterých byl průměr vypočítán. Tato hodnota se vypočítá jako odmocnina z podílu rozptylu a počtu měření – jde o hodnotu přesnosti odhadu průměru výběrového souboru = střední chyba průměru, nejčastěji se značí S.E. (z anglického standard error of mean). Vedle směrodatné odchylky je střední chyba průměru druhou nejdůležitější charakteristikou variability průměru, tentokrát ale nikoliv ve vztahu k vlastním měřeným datům (jak je tomu u směrodatné odchylky) ale k průměru základního souboru – všimněte si ve vzorci, že je závislá na počtu měření – čím je počet měření větší, tím je menší S.E. při stejné hodnotě průměru i směrodatné odchylky. V R je třeba aktivovat package sciplot a v něm je to funkce se(). V MS Excel se při výpočtu S.E. lze naučit používat dříve zmíněnou funkci MS Excel – POČET – která vrátí počet buněk v poli dat a je v podstatě zjednodušenou variantou dříve poznané funkce ČETNOSTI. Taktéž si ukážeme možnosti použití více funkci a vkládání funkcí do funkcí na příkladu výpočtu střední chyby průměru = SMODCH.VÝBĚR(A2:A22)/ODMOCNINA(POČET(A2:22)), další poznanou funkcí tak bude ODMOCNINA.
Třetí charakteristikou variability průměru jsou pak konfidenční intervaly spolehlivosti průměru. Jde o interval v němž s nějakou mírou pravděpodobnosti průměr leží. Průměr sám je samozřejmě bodovým odhadem, ale už z S.D. je jasné, že data mají jistou variabilitu a všechny měřené hodnoty nemají obvykle hodnotu průměru. S ohledem na počet měření jsem pak schopen identifikovat míru pravděpodobnosti, ve které průměr “opravdu” leží. Obvykle se udává interval 95% – jde o interval, ve kterém s 95% pravděpodobností průměr leží (nejde tedy o bod, ale o interval hodnot). Vypočítá se jako hodnota průměru plus/mínus kritická hodnota testovacího kritéria pro hladinu významnosti alfa = 0,05 (najdeme ji u t-testu a je rozdílná pro rozdílné počty měření, potažmo stupně volnosti – k tomuto najdete vysvětlení u testování hypotéz).
Všechny potenciální objekty výzkumu tvoří základní soubor. Nejlepší samozřejmě je provést výzkum na všech objektech. Kromě toho, že je to nejlepší, je to ale v 99,9% případů nemožné. V drtivé většině případů tedy nemůžeme zkoumat všechny potenciální objekty, ale musíme z nich vybrat nějak “reprezentativní” vzorek, který můžeme pozorovat nebo na něm dělat pokusy. Tento soubor pozorování se označuje jako výběrový soubor.
Existuje široké spektrum způsobů, jak tento výběr provést – základním způsobem je náhodný výběr, který je nejlepším řešením. Jeho podstatou je, že každý jedinec základního souboru má stejnou šanci, že bude do výběrového souboru ze základního souboru vybrán. Pak mohu totiž zjištění z výběrového souboru vztahovat k základnímu souboru. Metody použité v základním kurzu počítají s tím, že studuji základní soubor nebo výběr, který je proveden náhodně.
Provedení takového výběru je však v drtivé většině případů nerealizovatelné (oproti tomu, co tvrdí statistici) a musíme téměř vždy volit horší postupy. Problémem je, že nenáhodný výběr je nutno hodnotit komplikovanějšími statistickými postupy. My se v základním kurzu budeme obvykle tvářit, že naše výběry jsou provedeny náhodně. V praxi nezapomínejte na prostorovou a časovou distribuci zkoumaných jevů. Čas a prostor mohou zásadně ovlivnit strukturu výběru, přestože na první pohled budete postupovat náhodně. Proto, pokud pro BP a DP budete dělat výběry buď zjevně nenáhodně nebo budete mít podezření na narušení náhodnosti vlivem prostoru nebo času, tak se podívejte nejprve na příslušné pasáže z navazujícího kurzu.
PAMATUJTE!!!!! – výběr vzorku, stejně jako design experimentu, zásadně ovlivňují možnosti jeho “statistického” zpracování.
Charakteristiky získaného souboru dat bývají podceňovány, nicméně jejich význam je nenahraditelný a u nich by mělo začít každé další zpracování. Podávají nám sumarizované a reprezentativní informace o obsáhlých a okometricky nepojmutelných závalech obvykle “nic neříkajících” čísel. Drtivou většinu z nich umí vytvořit MS Excel pomocí funkcí, nebo si můžete výpočet jednoduše udělat sami, pokud víte, jak se daná charakteristika vypočítá 🙂
Vzhledem k tomu, že většina lidí má tendenci chápat oblast okolo průměru jako hodnoty nejčastěji se vyskytující v souboru dat, je vhodné průměr doplnit o další ukazatele, které nás z tohoto omylu rychle vyvedou:
Nezapomínejme, že svůj význam při hodnocení mají i další základní ukazatelé, kterými jsou minimum (MIN) nebo maximum (MAX). Stejně tak nás často zajímají charakteristiky centrální tendence z výše uvedených ukazatelů, pokud máme větší počet výběrů z jednoho základního souboru. Obvykle se používá k validaci provedeného výběru, kupříkladu s cílem kalibrace. Nejčastěji se v tomto případě používá aritmetického průměru z průměrů vypočítaných z většího počtu měření z více výběrů.
MS Excel umí i některé další funkce, např:
Charakteristiky polohy nás informují o “průměrné” charakteristice souboru dat. Získaná data však obvykle obsahují i pozorování, která jsou od hodnoty “průměru” značně odlišná. Charakteristiky vnitřní odlišnosti dat jsou tak stejně důležité. K základním patří:
Oblíbenou grafickou vizualizací charakteristik polohy a variability je často krabicový graf (box-plot). Podle typu dat zobrazuje různé z výše uvedených hodnot. Ani jednu variantu však MS Excel jednoduše sám “vyrobit” neumí a je nutné si data sama/sám připravit. Nejjednodušší případ box-plotu, který zobrazuje bodem hodnotu mediánu, “krabicí” 1. a 3. kvartil a “vousy” minimální a maximální hodnotu. V tomto případě vycházíme ze sloupcového grafu, kde boxy jsou de facto částí sloupce podle 1. 2. a 3. kvartilu a “vousy” jsou konstruovány jako chybové úsečky. Z tohoto je zřejmé, že pro konstrukci takového box-plotu potřebujeme umět z dat vypočítat charakteristiky polohy a umět pracovat s grafy MS Excel. Výpočet potřebných údajů je na videu, stejně jako tvorba vlastního box-plotu na druhé části videa.
Výpočet potřebných údajů pro sestavení box-plotu (nějak mi tam ujel medián u veg3, ale to pro naše potřeby nevadí).
Vytvoření box-plotu ze sloupcového skládaného grafu.
Doma si můžete instalovat doplněk Real Statistics, kde je na tento základní případ nástroj BoxPlot – schopen je pracovat i se zápornými daty. “Pravé” box-ploty mohou označovat různé hodnoty (tabule) – k tomu ale budete muset využít jiný software než je MS Excel.

Přehled základnách typů box-plotů.
Četnost znamená počet výskytu daného jevu (např. samců), hodnoty (např. kategorie “velmi mnoho” nebo teploty 0°C) nebo intervalu hodnot (např. pH 3,5-4) v souboru dat. Četnosti mohou být vyjádřeny dvěma způsoby: (1) absolutně = počet hodnot v každé kategorii (výstupem takovéhoto zpracování je obvykle tabulka), (2) relativně = počet hodnot v každé kategorii je vydělen celkovým počtem měření, tedy celkový součet je 1 nebo 100, pokud každý podíl vynásobíte stem – jde o procenta (těchto výstupů se volí pro konstrukci poměrových grafů – koláčové, skládané sloupcové nebo pruhové).
Základním nástrojem pro četnostní zpracování nominálních, ordinálních a dopředu kategorizovaných intervalových či poměrových dat je kontingenční tabulka. Ty mohou být jednorozměrné = pro jednu proměnnou (tabule) nebo dvou a více rozměrných = pro dvě nebo více proměnných (tabule) – v základním kurzu se naučíme hodnotit jen dvourozměrné tabulky.

Princip tvorby dvourozměrné kontingenční tabulky.

Vícerozměrná kontingenční tabulka.
Nejčastěji používáme dvě proměnné a rozdíly v nich pak testujeme pomocí testu dobré shody. Video základní práce s nominálními a ordinálními daty.
Práce s nominálními a ordinálními daty v kontingenční tabulce.
Pokud chceme stejným způsobem zpracovat intervalová a poměrová data, je z nich třeba nejprve vytvořit kategorie – viz tabule.

Kategorizace poměrových proměnných.
Možností jak toho v MS Excel dosáhnout je více. Nejjednodušeji ale zároveň nejpracnější je ruční nahrazování (takto to dělat nebudeme). Nejrychlejší postup je přes funkci ČETNOSTI (stačí si do volného sloupce stanovit hranice intervalů a MS Excel Vám vyhodí počty měření v jednotlivých intervalech). Druhou, komplikovanější možností je použití funkce COUNTIF, což je asi nejgeniálnější funkce MS Excel, která toho umí strašně mnoho a budete-li v budoucny někdy řešit komplikovanější úlohy, pak se bez ní neobejdete, nicméně zde by to znamenalo počítat četnosti postupně pro jednotlivé kategorie (funkce ČETNOSTI je v tomto případě elegantnější). Postup je zdlouhavý a my jej dělat nebudeme, pokud se to chcete naučit tak tady je externí videonávod a to, co potřebujete vědět, je ve stopáži 27:50 až 39:20. Obě výše uvedené funkce Vám však vrátí jednorozměrnou kontingenční tabulku, což bude často problém pro Vaše další výpočty – Vy často budete chtít přiřadit kategorii ke konkrétnímu měření. Toho lze dosáhnout funkcí, kterou už známe z databází, a to SVYHLEDAT, kde jako typ zadáte hodnotu 1 (jinak je postup stejný jako u spojování tabulek, POZOR!!! zadává se spodní hranice intervalu) – video.
Použití funkce SVYHLEDAT pro vytvoření kategorií.
Kontingenční tabulka má pro poměrová data ještě jednu výhodu. Jste pomocí ní schopni získávat velmi rychle charakteristiky polohy i variability pro Vámi zvolené kategorie – model využití je na videu.
Kategorizované charakteristiky polohy a variability v kontingenční tabulce.
Druhým nástrojem pro posouzení četností je histogram. Jedná se o graf četností. Obvykle na ose x jsou kategorie a na osu y jsou vynášeny hodnoty četností. Stejně jako u kontingenčních tabulek, tyto četnosti mohou být vyjádřeny absolutně nebo relativní stupnici. Lze do jednoho histogramu vynést více proměnných (měřených na stejné stupnici a kategorizovaných do stejných intervalů či kategorií). Samozřejmě, že když se jedná o ordinální nebo kategorizovaná poměrová data, tak na ose x jsou kategorie řazeny obvykle vzestupně. Vytvoření histogramu v MS Excel není v základu možné. Lze k jeho vytvoření použít výše zmíněné funkcí četnosti COUNTIF. Ale optimální je využití kategorizace provedené přes SVYHLEDAT. Užití si ukažme na pokračování příkladu ke kategorizaci poměrové proměnné – video.
Vytvoření histogramu v MS Excel.
Další možností je využití vytvoření histogramu přes kartu Vložit – histogram nebo nástroje Histogram na kartě Analýza dat, ale k ní se ale dostaneme až časem.
Dalším způsobem vyjádření četností histogramem je tzv. kumulativní histogram. V něm jsou postupně načítány hodnoty předchozích k následujícím kategoriím. Pokračujme v předchozím příkladu na videu. Kumulativní relativní četnosti budeme potřebovat při výpočtech nutných k posouzení normality dat.
Vytvoření histogramu kumulativních četností.
Histogramů se také často používá, když chceme rychle okometricky posoudit, jaké rozložení naše hodnoty mají. K tomu se dostaneme u náhodných veličin.
Přestože MS Excel není určen k tvorbě, uchovávání a zpřístupnění databázových dat, je jako program pro jednoduché databáze zcela běžně používaný. Pro Vaše BP a DP budete MS Excel asi používat nejčastěji. Pokud máte jednu skupinu dat, je obvykle účelné uchovat data na jediném listu = v jediné tabulce.
Často však máme k dispozici různé skupiny dat. Pak je vhodné mít uloženy informace v různých tabulkách (v MS Excel každá tabulka na svém listu) – nejjednodušší variantou jsou tzv. relační databáze. Jejich podstatou je možnost propojení různých tabulek přes tzv. klíče = jednoznačné identifikátory záznamu – přes ně jsme schopni propojovat jednotlivé tabulky databáze a tvořit výstupové tabulky určené ke statistické analýze. Podstatné u těchto klíčů (ale i všech záznamů v jednotlivých sloupcích) je, aby v každém klíči (a sloupci) byly pouze záznamy, které splňují podmínku, že mají pouze požadovaný typ dat a konkrétní hodnoty jsou z nějaké přípustné množiny dat. Tato podmínka je právě problematická v MS Excel, neboť ten Vám umožní napsat cokoliv kamkoliv (u databázových programů si nejprve volíte charakteristiky proměnné a pak je Vám umožněno vložit jen konkrétní hodnoty), proto je třeba dbát na přesnost tvorby záznamů – každá přebytečná mezera má za následek chybná přiřazení (obvykle nepřiřazení) v relacích. Proto jsme v typech dat upozorňovali na problematiku zadávání dat (možností ,jak se chyb vyvarovat, jsou formuláře pro zadávání dat). U relačních databází pak tedy platí, že lze na základě klíčů z různých tabulek přiřazovat do různých tabulek nejrůznější údaje.
My této části věnované práci s databází využijeme především pro poznání práce s textovými funkcemi MS Excel. Nejdůležitější nástroje pro jejich ovládání si ukážeme na řešení konkrétního projektu.
Příklad: Máme dvě databáze – databázi pěstovaných rostlin a databázi informací k rostlinným druhům. Za úkol máme vytvořit ke každému pěstovanému exempláři cedulku, kde bude identifikační kód daného exempláře a základní informace o systematickém zařazení.
Práce s textovými funkcemi v MS Excel
Použití funkce SVYHLEDAT v MS Excel
Použití formulářů pro zobrazení dat v MS Excel
Existují čtyři základní typy dat:
Většina statistických metod je určena pro data poměrová, často se však používají i na data ordinální, pokud můžeme alespoň částečně tvrdit, že jejich stupnice jeví známky “poměrovosti” a získaná data mají něco na způsob normálního rozdělení (statisticky to správně není, ale při velkém počtu měření se to běžně dělá). Na druhou stranu velké množství dat, které budete sbírat, má charakter dat nominálních, často binárních (nejčastěji pohlaví, presence/absence data, přežil/nepřežil, vyklíčil/nevyklíčil). Ve společenských vědách máme většinu dat pocházejících z dotazníků typu ordinálního (respondenti v dotazníkových šetřeních jsou nejčastěji nuceni odpovídat na různých škálách), nicméně na ně často aplikujeme metody určené na data poměrová – nejčastěji na ně budete aplikovat jednofaktorovou analýzu rozptylu (ANOVA) nebo t-testy, když budete hledat rozdíly mezi kategoriemi, to není statisticky vůbec dobře, ale také se to běžně dělá.
Pro poměrová data pak platí, že mohou být spojitá, pokud lze mezi jakýmikoliv dvěma hodnotami nalézt jinou hodnotu, nebo nespojitá (diskrétní), pokud tato podmínka není splněna – nejčastěji jde o počty. Je-li počtů mnoho, pak se obvykle k diskrétním datům chováme, jako by byla spojitá.
Jako nejvýhodnější pro většinu získaných dat se jeví jejich uchovávání v jednoduché databázové struktuře. To znamená, že v každém sloupci je jedna proměnná a v každém řádku případ (= objekt, plocha, lokalita, respondent, jedinec, . . .). První řádek obsahuje “hlavičková data” – což jsou názvy proměnných (= jednotlivých sloupců). Skvěle se data připravují v tabulkových procesorech (buď ručně nebo přes nějaký zadávací formulář). Výhodou tabulkových procesorů je také přehlednost uložení dat umožňující vynikající platformu pro přemýšlení nad otázkou: “OK, mám data, ale co s nimi udělám?” Pokud data připravujete v MS Excel a ne v databázovém programu (což bude asi nejčastější případ), pak dodržujte následující pravidla:
Pokud pracujete v R, tak tam je filozofie zadávání dat úplně odlišná.
Poměrová a intervalová data zadáváte jako hodnoty:
Ordinální i nominální data lze zadat jako slova, ale pro MS Excel doporučuji zadávat je pomocí číselných kódů. Nicméně pro některé programy (např. Limdep nebo Canoco) jsou v případě nominálních dat rozhodně vhodnější slova (obvykle jde o zkratky) – software je pak nebere jako poměrové proměnné a automaticky je bere jako nominální:
Ke kódům je zapotřebí vždy někam uložit klíč – za týden už obvykle netuším, že 3 je červená, nebo že 1 je “určitě ano” a ne “určitě ne”. Obvykle tendujeme z lenosti k tomu, že si vysvětlivky ke kódům nepíšeme (do týdne ale už nevíme, co které číslo znamená) nebo si je píšeme někam na papír od svačiny (ten ještě toho večera zahodíme). Jako jediné vhodné se jeví striktně dělat všechny vysvětlivky okamžitě do stejného souboru, kde máme data, ale samozřejmě na jiný list, který si pojmenujeme “kódy” nebo “vysvětlivky”.
Z tohoto základního modelu zadávání dat se vymyká tzv. dummy kódování nominálních proměnných. To si vyžadují především mnohorozměrné metody, nicméně i některé základní statistické postupy – např. neparametrické korelace (Spearmanův korelační koeficient nemůžeme použít na nominální data zadaná postupem uvedeným výše). Zásadním rozdílem je, že v tomto kódování není daná nominální proměnná v jednom sloupci, ale v tolika sloupcích, kolik je kategorií dané proměnné (pokud je používáme v mnohorozměrných metodách jako vysvětlující proměnné, tak je to počet proměnných snížených o jedna (např. máme-li třístupňovou proměnnou “rula, žula, svor”, tak stačí informace k prvním dvěma, v nich je již i informace o třetí proměnné – pokud je u ruly a žuly nula, je jasné, že to musí být svor). Každá kategorie se pak kóduje binárně 1 = ano, 0 = ne.
Příklad bílá-modrá-červená: budou dva sloupce – bílá a modrá, pokud je daný případ bílá, pak bude ve sloupci bílá 1 a ve sloupci modrá 0; pokud je daný případ modrá, pak bude ve sloupci bílá 0 a ve sloupci modrá 1; pokud je daný případ červená, pak bude ve sloupci bílá 0 a ve sloupci modrá 0 (má-li kytka jen tři barvy a nemá-li květ bílý ani modrý, je jasné, že květ je červený)
POZNÁMKA: každý software může mít své vlastní požadavky na to, jak mají být data zadána, aby daná statistika šla vypočítat – viz např. dvouvýběrový t-test v MS Excel.
V některých případech je nutné data k jednomu měření (= jednomu objektu) zaznamenat na více řádků – takovýmto datům se říká “panel data”. Pokud je u každého měření stejný počet řádků, pak jsou data “ballanced”, pokud ne, pak jsou “unballanced”. To je důležité nastavit v software určených pro jejich zpracování, aby program provedl správný výpočet.



{kind=link}