
Bryophytes
Non-vascular land plants - liverworts, mosses, and hornworts.



Máme-li více výběrů než dva, nemůžeme řetězit dvouvýběrové t-testy ani jejich neparametrické varianty, ale musíme použít speciální metody výpočtu označované obecně jako ANOVA a její neparametrické obdoby. Dostáváme se na půdu lineárních modelů a jejich neparametrických rozšíření a tedy půdu již poměrně komplikovanou 🙂
Všechny na tomto postu uvedené testy naleznete v 9. Lekci R.
Mám data z více výběrů, které jsou nezávislé, ale mohou být závislé.
1a Data jsou poměrová a splňují podmínku homogenity variancí a pocházejí ze souborů s normálním rozdělením . . . 2 ANOVA
1b Data výše uvedenou podmínku nesplňují nebo nejsou poměrová . . . 3 neparametrické testy
2a Všechny výběry nezávislé . . . klasická ANOVA
| ANOVA | vyvážený design | nevyvážený design |
| jednofaktorová | Typ I | Typ III |
| hlavní efekt | Typ I | Typ II |
| vícefaktorová | Typ I | Typ III |
| nested | Typ I | Typ III |
2b Alespoň jeden výběr závislý . . . RMANOVA
Klasická ANOVA i RMANOVA mohou pracovat s faktory s pevnými efekty i náhodnými efekty.
3a Všechny výběry nezávislé . . . Kruskal-Wallis test
3b Alespoň jeden výběr závislý . . . Friedmanův test
Tento test je základní a používáme ho, chceme-li posoudit hypotézu o rovnosti průměrných hodnot více než dvou výběrů. Předpoklady použití ANOVA jednoduchého třídění jsou:
Užití si můžeme demonstrovat na následujících příkladech:
1. Nejprve testuji poměr variance uvnitř definovaných skupin (typ vegetace nebo typ návštěvníka hradu podle vztahu k historii) a rozptylu celkového souboru získaných dat. Jde tedy v podstatě o F-test. Rozptyly zde jsou označovány jako MS (F= MS(celek)/suma MS(ve skupinách)). Rozptyly jsou určeny jako podíly součtu čtverců odchylek od průměrů a počtu stupňů volnosti. Přehled informací k prvnímu kroku je na tabuli.

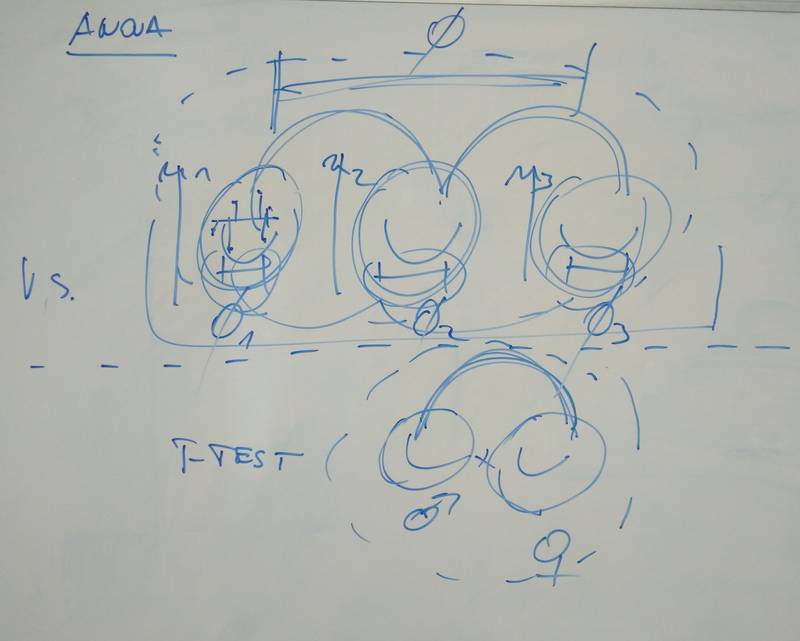
2. Pokud zjistím, že hodnota F je vyšší než kritická hodnota pro daný počet stupňů volnosti (= p je menší než stanovená hladina významnosti), pak vím, že v mém souboru dat existují rozdíly mezi skupinami, musím se proto dále ptát: “Jaké skupiny vegetace nebo jaké skupiny návštěvníků hradu se od sebe liší?” Následuje tedy fáze mnohonásobného porovnávání, kdy se testuje rozdílnost skupin pomocí tzv. post-hoc testů. K nim je obvykle nutné znát dosažené hodnoty rozptylů, stupně volnosti a počet měření pro jednotlivé testované skupiny. Těchto testů je mnoho, obecně se používá Tukeyho post-hoc test, jehož výpočet je odvozen od t-testu a má variantu pro vyvážený i nevyvážený design. Kritické hodnoty pro jeho q statistiku lze nalézt na externím odkazu (R počítá přímo i hodnotu p). Přehled informací ke druhému kroku je na tabuli.

Analogií Tukeyho post-hoc testu je Dunnettův post-hoc test, kterým porovnáváme nikoliv všechny skupiny mezi sebou, ale všechny skupiny s kontrolní skupinou. Použije jej tedy, pokud provádíme experiment, kde máme jednu bezzásahovou skupinu (= kontrolu).
Další testům “klasické” ANOVA se budeme věnovat podrobněji v navazujícím kurzu.
Postup řešení výpočtu jednofaktorové ANOVA v MS Excel je na videu.Postup výpočtu Tukeyho post-hoc testu v MS Excel je na videu.Dunnettův post-hoc test se dá vypočítat i v MS Excel, jako je na externím videu. Ve STATISTICA jej najdete v dialogovém okně ANOVA Results na kartě post-hoc úplně dole (pokud znáte směr, tak můžete použít jednostranného testu; nezapomeňte nastavit, která úroveň je kontrola).
Postup řešení výpočtu jednofaktorové ANOVA v MS Excel je na videu. Postup výpočtu Tukeyho post-hoc testu v MS Excel je na videu. Dunnettův post-hoc test se dá vypočítat i v MS Excel, jako je na externím videu. Ve STATISTICA jej najdete v dialogovém okně ANOVA Results na kartě post-hoc úplně dole (pokud znáte směr, tak můžete použít jednostranného testu; nezapomeňte nastavit, která úroveň je kontrola).
Je-li One-way ANOVA analogií dvouvýběrového t-testu pro více výběrů, pak RMANOVA je obdobou pro párový t-test, kde máme více opakování než jedno. Tento test použijete v případech, když výběry nejsou vzájemně nezávislé – typicky, když měříte jeden objekt více než dvakrát. Výpočet v R se odvíjí od výpočtu vícefaktoriální ANOVA (viz navazující kurz).
Použití MS Excel pro tento výpočet máte na externím zdroji.
Pokud jsou předpoklady pro použití ANOVA výrazně porušeny, používáme Kruskal-Wallis test. Ten je neparametrickou obdobou testu (jedno)faktorové ANOVA. Podobně jako Mann-Whitney test, je i výpočet Kruskal-Wallis testu založen na pořadí. Používáme ho v případě, kdy je zjevně porušena normalita v rozložení měřených dat – což se v terénu obvykle stává často – nebo máme ordinální data. Kruskal-Wallis test se běžně používá a v mnoha případech je jeho použití správnější než ANOVA jednoduchého třídění. Vše podstatné je na tabuli.

Tabulka kritických hodnot je na např. na externím odkazu 1 nebo externím odkazu 2. Také u Kruskal-Wallis testu je v případě prokázání rozdílů mezi skupinami nutné provést test shody dvojic měřených úrovní. Existuje mnoho takových testů, ale nejčastěji se provádí Mann-Whitney testem pro jednotlivé páry s upraveným p podle Bonferoniho korekce – blíže na externím odkazu.
STATISTICA má tento test schován v nabídce karty “Nonparametrics” pod označením “Comparing multiple indep. samples (groups)”.
Je-li Kruskal-Wallis test analogií Mann-Whitney testu pro více výběrů, pak Friedmanův test je obdobou pro Wilcoxonův test, kde máme více opakování než jedno. Tento test použijete v případech, když výběry nejsou vzájemně nezávislé – typicky, když měříte jeden objekt více než dvakrát a zároveň máte porušeny pravidla pro použití RMANOVA (především často nemáte “normální” data).
Příklady jsou stejné jako v případě RMANOVA, jen data nesplňují podmínky použití RMANOVA.
Použití MS Excel pro tento výpočet máte na externím zdroji.